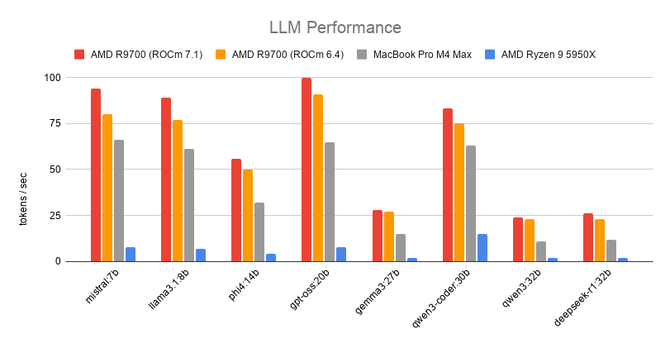
I benchmarked LLM performance on AMD Radeon AI PRO R9700 with Ollama, comparing ROCm 7.1 vs 6.4 across 8 models (Mistral, Llama, Qwen, GPT-OSS, DeepSeek, and more). Result: visible gains in prompt throughput (+87% avg) and faster responses (+11% avg). Full tables, setup, and notes in the post.https://meefik.dev/2026/05/31/llms-performance-rocm7/#AMD #ROCm #Ollama #LLM #AI
I benchmarked LLM performance on AMD Radeon AI PRO R9700 with Ollama, comparing ROCm 7.1 vs 6.4 across 8 models (Mistral...