Meta AI veröffentlicht das multimodale Modell Tuna-2, das Bildinhalte ohne klassische Vision-Encoder verarbeitet.Die Architektur liest rohe Pixel direkt über Patch-Embeddings ein und umgeht VAE-Module. Beim OCRBench zeigt Tuna-2 bessere Werte als vergleichbare Systeme. Das Training zwingt Transformer-Decoder durch das Verdecken von Bildbereichen zur eigenständigen Erkennung visueller Strukturen.#MetaAI #Tuna2 #MultimodalAI #LLM #AIGeneratedImagehttps://www.all-ai.de/news/news26/meta-tuna2-neu
Related
2026-05-16 | 🤖 🌌 The Recursive Echo of the Collective 🤖#AI Q: 🤖 If you could encode one non-negotiable value into a mach...
2026-05-16 | 🤖 🌌 The Recursive Echo of the Collective 🤖#AI Q: 🤖 If you could encode one non-negotiable value into a machine, what would it be?🕸️ Mesh Governance | 🧠 Digital Identit...
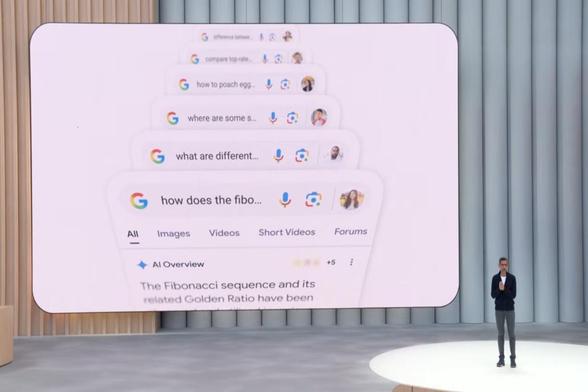
https://winbuzzer.com/2026/05/17/google-search-spam-policy-ai-overviews-ai-mode-manipulation-xcxwbn/Google hasupdated it...
https://winbuzzer.com/2026/05/17/google-search-spam-policy-ai-overviews-ai-mode-manipulation-xcxwbn/Google hasupdated its Search spam policy to classify attempts to manipulate gene...
Eric Schmidt booed at University of Arizona after praising AIhttps://bsky.app/profile/404media.co/post/3mm2ivguvq22x#404...
Eric Schmidt booed at University of Arizona after praising AIhttps://bsky.app/profile/404media.co/post/3mm2ivguvq22x#404media #ai