Orthrus-Qwen3: up to 7.8×tokens/forward on Qwen3, identical output distributionOrthrus-Qwen3은 Qwen3 기반 대형 언어 모델(LLM)의 추론 속도를 최대 7.8배까지 가속하는 병렬 토큰 생성 프레임워크입니다. 이중 뷰 확산 디코딩 방식을 사용해 원본 모델과 동일한 출력 분포를 엄격히 보장하면서도 메모리 오버헤드를 최소화합니다. 기존의 추측적 디코딩 기법 대비 높은 토큰 수용률과 빠른 추론 속도를 제공하며, 복잡한 추론 작업에서도 정확도 저하 없이 병렬 생성을 구현합니다. 파인튜닝은 전체 파라미터의 16%만 수행해 효율적입니다. vLLM과의 네이티브 통합도 예정되어 있어 AI 인프라에 즉시 적용 가능한 혁신적 기술입니다.https://github.com/chiennv2000/orthrus#llm #inference #parallelgeneration #diffusionmodel #qwen3
Related
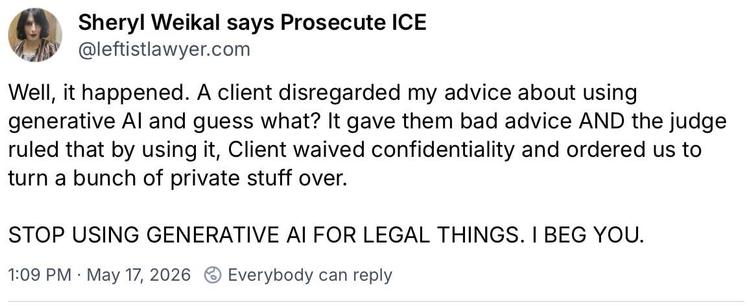
Dang https://bsky.app/profile/leftistlawyer.com/post/3mm2u3rqnyk2l#AI #Privacy
Dang https://bsky.app/profile/leftistlawyer.com/post/3mm2u3rqnyk2l#AI #Privacy
A tech overlord gets a basic lesson in how foisting a largely unwanted, fraudulent technology that's destroying the plan...
A tech overlord gets a basic lesson in how foisting a largely unwanted, fraudulent technology that's destroying the planet, the world wide web, knowledge in general, and making it ...

📰 European AI Sovereignty: Mistral CEO's 2-Year Warning to Avoid US Vassal State Status (2026)The CEO of French AI start...
📰 European AI Sovereignty: Mistral CEO's 2-Year Warning to Avoid US Vassal State Status (2026)The CEO of French AI startup Mistral has issued a stark warning, stating that Europe f...