[AINews] Sonnet 5 today, and Fable 5 tomorrow
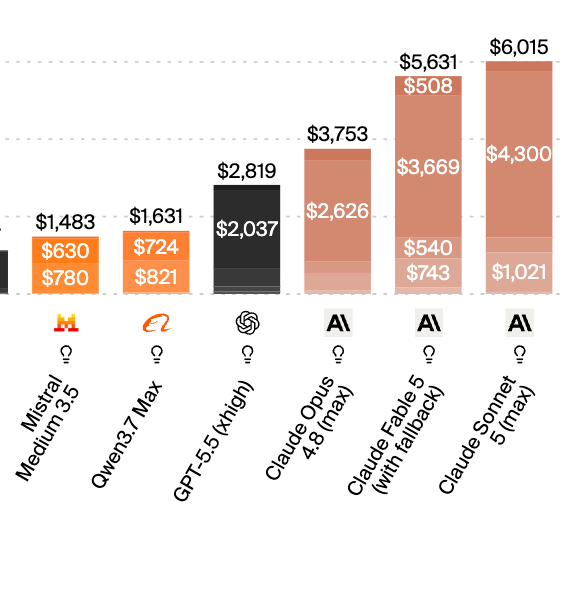
In separate announcements, Sonnet 5 was released today, and Fable/Mythos 5 were approved to be released again after some work with the government. The primary discussion around Sonnet 5’s efficiency was a damper on the excitement, driven by tokenizer changes and 3-6x more turn taking in benchmarks:Our newest staff writer is reporting on the ground from AIE, and you can catch swyx and other keynote speakers on the stream today:AI News for 6/29/2026-6/30/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!AI Twitter RecapAnthropic launched Claude Sonnet 5 as its new default mid-tier frontier model, with immediate rollout across Claude, Claude Code, API, and ecosystem partners.Anthropic officially announced Claude Sonnet 5 as “our most agentic Sonnet yet,” emphasizing planning, browser/terminal tool use, and autonomous execution that previously “required larger and more expensive models” (@claudeai)Anthropic’s developer account said Sonnet 5 offers top-tier coding and tool-use performance at Sonnet pricing, with a 1M-token context window, and is the new default in Claude Code for Pro users and available on the Claude Platform including API and Managed Agents (@ClaudeDevs)Anthropic kept the standard list price at $3/M input tokens and $15/M output tokens, but introduced a promotional rate of $2/M input and $10/M output through Aug. 31 / Sept. 1 depending on the post (@kimmonismus, @ClaudeDevs, @ArtificialAnlys)Sonnet 5 surfaced first through leaks and client-side sightings: leakers claimed knowledge cutoff January 2026, $2/$10 promo pricing, and a 1M-context variant before launch (@kimmonismus); users then reported it appearing in the model selector, Claude Code 2.1.197, Anthropic GitHub, and finally going live in accounts including Germany (@kimmonismus, @scaling01, @scaling01, @kimmonismus)Anthropic simultaneously expanded platform support around the launch: Claude Desktop on Linux (Ubuntu/Debian beta) with Claude Code/Cowork/chat on paid plans, though Computer Use was not included in that Linux release (@ClaudeDevs, @ClaudeDevs)Anthropic also shipped Managed Agents updates—streaming session deltas, per-session overrides, webhook events, reverse pagination, credential injection scoping, and an observability tab with token/tool metrics—making the release as much platform/integration story as raw model story (@ClaudeDevs, @ClaudeDevs)Launch timeline and pre-release narrativeThe launch was preceded by a large rumor cycle centered on Sonnet 5 + Fable 5.Earlier app-string sleuthing suggested Anthropic was preparing to put “Fable 5” behind a separate usage-credit system billed outside existing plans, with identity verification language appearing nearby; that fed speculation that access would be gated and more regulated than existing plans (@kimmonismus)This triggered concern that Sonnet 5 might launch as the widely accessible but weaker companion to a stronger, more restricted Fable 5, possibly with regional access issues, especially in Europe (@kimmonismus)Additional rumor posts tied a potential Sonnet 5 release directly to a Fable 5 re-release, with some users explicitly saying they assumed Sonnet 5 would “at least” come with Fable news (@kimmonismus, @kimmonismus)After launch, that expectation went unmet. Multiple reactions framed the absence of Fable 5 as the real story: “instead we got sonnet 5” (@kimmonismus) and “It’s been 18 days since Fable 5 was banned” (@theo)Official positioning vs independent interpretationOfficial/vendor framingAnthropic and downstream partners framed Sonnet 5 around agentic capability, coding, tool use, and cost-performance.Official claim: Sonnet 5 is the “most agentic Sonnet yet” and can make plans, use browsers/terminals, and operate autonomously at a level that recently required larger models (@claudeai)Anthropic’s dev account positioned it as frontier-quality coding and tool use at Sonnet pricing, explicitly highlighting 1M context and broad platform availability (@ClaudeDevs)Anthropic-linked summary posts stressed that Sonnet 5 is safer than Sonnet 4.6 overall, with lower hallucination and sycophancy, and that cyber safeguards are on by default, while still acknowledging Opus remains stronger for serious cyber work (@kimmonismus)Anthropic also provided migration tooling/documentation, saying the claude-api skill helps tune prompts, recommend effort levels, and configure advisor mode for Sonnet 5 (@ClaudeDevs)Independent/third-party evaluation framingThird parties largely agreed Sonnet 5 is a real improvement over Sonnet 4.6, but disputed whether it merits a “5.0” naming step or its effective price/performance relative to Opus and peers.Cursor said Sonnet 5 is a meaningful step up on CursorBench: 57% vs 49% for Sonnet 4.6 (@cursor_ai)Cognition said Sonnet 5 outperforms Opus 4.8 on FrontierCode Extended, posting 53.8% score and 57.6% pass rate, while noting benchmark rankings may shift slightly after upcoming adjustments (@cognition, @cognition)Cline highlighted Opus 4.8-level performance on Terminal-Bench for less than half the cost, plus improved resistance to prompt-injection hijacks for “--yolo coders” (@cline)FactoryAI, Perplexity, Cursor, Devin, Droid, Agent Arena, and VS Code all quickly added support or availability announcements, indicating the ecosystem saw it as a relevant default model even where user enthusiasm was mixed (@FactoryAI, @perplexity_ai, @AravSrinivas, @code, @arena, @cognition)Technical detailsCore product specs and pricingContext window: 1 million tokens (@ClaudeDevs, @ArtificialAnlys)Standard pricing: $3/M input, $15/M output (@ClaudeDevs, @ArtificialAnlys)Promotional pricing: $2/M input, $10/M output until Aug. 31 / Sept. 1 depending on wording of the post (@kimmonismus, @ArtificialAnlys)Cache pricing: 25% premium for cache writes ($3.75/M), 90% discount for cache hits ($0.3/M), 5-minute TTL (@ArtificialAnlys)Effort settings: Sonnet 5 adds xhigh, for 5 effort levels total matching Opus 4.8: max, xhigh, high, medium, low (@ArtificialAnlys)Knowledge cutoff (rumored pre-launch): January 2026 (@kimmonismus)Benchmarks and measured deltasA key part of the discussion was that Sonnet 5 improved substantially over 4.6, but usually did not exceed Opus 4.8 on broad intelligence aggregates.CursorBench: 57% for Sonnet 5 vs 49% for Sonnet 4.6 (@cursor_ai)Artificial Analysis Intelligence Index: Sonnet 5 scores 53, a +6 over Sonnet 4.6, placing it #5 overall, roughly tied with GPT-5.5 high reasoning, but still behind Opus 4.7/4.8 (@ArtificialAnlys)Artificial Analysis token usage: Sonnet 5 used ~69k output tokens per task on average, about 40% more output tokens than Sonnet 4.6 (@ArtificialAnlys)Artificial Analysis task cost: at standard pricing, Sonnet 5 cost $2.29 per Intelligence Index task, about 2x Sonnet 4.6 and ~15% more than Opus 4.8, despite lower per-token price, because of higher token usage (@ArtificialAnlys)Agentic turns: Sonnet 5 used ~3x the agentic turns of Sonnet 4.6 on AA-Briefcase and GDPval-AA, and max effort used around 6x more turns than low effort on GDPval-AA (@ArtificialAnlys)CritPt frontier physics benchmark: Sonnet 5 scored 17%, +14 points over its predecessor, but still behind GLM-5.2, Claude Opus, Fable, and GPT-5.5 variants (@ArtificialAnlys)Artificial Analysis also reported notable improvements over Sonnet 4.6 on Terminal-Bench v2.1 (+9), Humanity’s Last Exam (+10), and SciCode (+7) (@ArtificialAnlys)Cognition’s FrontierCode Extended result: 53.8% score, 57.6% pass rate, ahead of Opus 4.8 in their current evaluation (@cognition)Max Bittker noted Runescape benchmark scores improved a lot over Sonnet 4.6, but were still behind nearby Pareto competitors such as GLM 5.2 and Gemini 3.5 Flash (@maxbittker)Tokenization and effective cost quirksOne underappreciated technical detail was the tokenizer/effective billing behavior.Simon Willison noted the new tokenizer makes Sonnet 5 ~1.4x more expensive for English, ~1.33x for Spanish, and roughly the same for Simplified Mandarin (@simonw)This matters because many users compared only list prices, while evaluators and power users focused on cost per solved task, not just cost per tokenFacts vs opinionsFactual claims supported by official or benchmark postsSonnet 5 launched officially and is available in Claude, Claude Code, API, Managed Agents, and many partner products (@claudeai, @ClaudeDevs)It has a 1M-token context window (@ClaudeDevs)Standard pricing is $3/$15 per million input/output tokens with a temporary promo of $2/$10 (@ClaudeDevs, @ArtificialAnlys)Third-party results show meaningful gains over Sonnet 4.6 on coding/agentic benchmarks including CursorBench, FrontierCode Extended, and Artificial Analysis (@cursor_ai, @cognition, @ArtificialAnlys)Artificial Analysis found Sonnet 5 can cost more per task than Opus 4.8 because it uses more tokens/turns (@ArtificialAnlys)Rumors / unverified claimsFable 5 billing changes, identity verification, and regulatory linkage came from app-string interpretation and user speculation, not from an official launch note (@kimmonismus)January 2026 knowledge cutoff and some launch/pricing details were leaked before confirmation (@kimmonismus)Claims that Sonnet 5 was intentionally nerfed, self-distilled just enough to remain below Opus, or launched due to a soft ban on frontier capabilities are opinions/speculation, not evidenced in the official materials (@scaling01, @z4y5f3, @kimmonismus)Interpretive opinionsPositive interpretation: Sonnet 5 is the kind of smaller/cheaper model improvement that matters most for parallel workflows, long-running agents, and production coding systems (@The_Whole_Daisy, @omarsar0, @skirano)Negative interpretation: Sonnet 5 is underwhelming, overpriced in practice, and mislabeled as “5” when its aggregate capability looks closer to 4.8/4.9 than a major generational leap (@kimmonismus, @scaling01, @DeryaTR_)Neutral/engineering interpretation: This is a production-friendly release more than a hype release—better on coding/agents, broadly deployable, but not a flagship-redefining jump (@dejavucoder, @OpenAIDevs)Different opinionsSupporting viewsProduction users benefit most. Several posters argued Sonnet 5 is exactly the kind of model teams want for long-running agents, coding loops, and tool-use reliability, even if it doesn’t win every static benchmark (@omarsar0, @skirano)Smaller-model launches matter. Power users can underappreciate how much value comes from making a cheaper/default-tier model stronger, because that unlocks more parallel agents and redundancy in workflows (@The_Whole_Daisy)Coding benchmarks are strong. Cursor and Cognition both posted substantial results in practical coding/evaluation harnesses (@cursor_ai, @cognition)Security angle improved. Cline highlighted better resistance to prompt-injection/hijack attempts, relevant to autonomous terminal/browser usage (@cline)Critical viewsThe strongest criticism focused on naming, absent Fable 5, and poor task-level cost efficiency.Naming criticism: users argued “Sonnet 5” implies a major-version leap, while evals suggest something closer to Sonnet 4.8/4.9 (@kimmonismus, @teortaxesTex)Benchmark criticism: multiple users stressed Sonnet 5 still trails Opus 4.8 “across all evals” or on broad intelligence measures (@kimmonismus, @theo)Cost-per-task criticism: this became the most technically grounded negative theme. Theo, Yuchen Jin, Scaling01, and Kimmonismus all amplified that Sonnet 5 can be more expensive than Opus 4.8 or even Fable on actual evaluated tasks due to verbosity/turn count (@theo, @theo, @Yuchenj_UW, @kimmonismus, @scaling01)Launch disappointment tied to Fable 5: critics saw Sonnet 5 as a consolation release while the real frontier model remained withheld or constrained (@kimmonismus, @theo, @scaling01)Neutral / mixed takes“Production people will be happy; personal wow-factor is low.” That succinctly captures a recurring mixed reaction (@dejavucoder)Good release, bad expectation management. Some users seemed less upset by the model itself than by the implication that a “5.0” label and rumor cycle primed people for a more dramatic frontier jumpAgentic quality may be undermeasured. Some believed traditional benchmark comparisons may underrate improvements in what one poster called the model’s “working mind” on long-horizon tasks (@skirano)Ecosystem rolloutSonnet 5 was adopted unusually quickly across the coding-agent ecosystem, which is itself evidence of where the market thinks the value lies.Cursor added Sonnet 5 and published CursorBench deltas (@cursor_ai)Devin Desktop / CLI added it and claimed FrontierCode Extended outperformance versus Opus 4.8, plus temporary ~30% lower quota usage than Sonnet 4.6 through Aug. 31 (@cognition, @cognition)Cline added support and emphasized Terminal-Bench/cyber-hijack robustness (@cline)FactoryAI Droid added Sonnet 5 at 1/3 off until Aug. 31 (@FactoryAI)Perplexity added Sonnet 5 for Pro/Max and as a Computer orchestrator model (@perplexity_ai, @AravSrinivas)VS Code / @code rolled it out (@code)Arena added Sonnet 5 to Agent Arena and other arenas (@arena)This rollout pattern reinforces that Sonnet 5 is being treated less as a chatbot headline and more as a default workhorse model for agentic software stacks.ContextSonnet has historically been Anthropic’s price/performance workhorse and the model most likely to be used at scale in products like coding assistants, managed agents, and enterprise automation. That context matters for why the discourse split:Frontier-watchers expected a headline “5.x” eventBuilders wanted a better reliable default modelPower users benchmarked per solved task, not per tokenPolicy-aware observers interpreted the absence of Fable 5 and the earlier ID-verification/credit rumors as signs of tightening governance or staged accessThe launch also lands in a market where model differentiation is increasingly about:long-horizon tool useagent reliabilitytoken efficiencyeffective cost per completed taskintegration into work environments rather than pure chat demosThat is why reactions ranged from “clear upgrade” to “worst Anthropic launch.” Both are responding to real but different axes:On absolute capability vs Sonnet 4.6, it looks materially betterOn headline frontier progress vs Opus/Fable expectations, it disappointed manyOn list price, it looks affordableOn task-level cost, it can look surprisingly expensiveOn ecosystem utility, it was immediately embracedChina models, infrastructure, and open-weight competitionMeituan’s release drew the most attention outside Sonnet: an open-weights 1.6T-parameter model from a major Chinese delivery company, with discussion centering on how non-obvious Chinese incumbents can fund serious frontier-scale efforts (@JosephJacks_, @natolambert, @teortaxesTex)Technical scrutiny focused on hardware and scale details: claims that Meituan used CloudMatrix 384 pods in “910B mode”, implying ~25K chips not 50K GPUs-equivalent, while critics compared that to a future Huawei 950DT SuperPod with 8192 chips possibly outperforming the whole setup (@teortaxesTex, @teortaxesTex)DSpark/DeepSeek infra remained a major subtheme: posters highlighted TPOT of 2.9–5.2 ms, possible 50% throughput gains or 60% interactivity gains across Chinese providers, and the view that DeepSeek’s infra open-sourcing is creating broad economic spillovers (@teortaxesTex, @teortaxesTex, @Xianbao_QIAN)Huawei/Pangu and broader domestic stack momentum also came up: Pangu 92B / 6B active MoE open-sourcing in July was flagged, alongside repeated arguments that Chinese labs now have the software and architecture maturity to train near-frontier models on domestic hardware (@teortaxesTex, @teortaxesTex)Inference, chips, and systemsEtched’s stealth exit dominated hardware news: the company said it has $800M raised, $1B+ customer contracts, successful A0 tapeout, early SOTA throughput/latency/power efficiency in customer tests, and first racks shipping this summer (@Etched)Follow-on commentary described two notable hardware ideas: low-voltage inference to avoid thermal throttling under sustained load, and cluster-scale memory aimed at SRAM-like access speeds with larger pooled memory for long-context / giant-model inference (@LiorOnAI)OpenAI also reportedly found an inference optimization that more than halved inference costs, reducing logged-out ChatGPT traffic to “a couple hundred” GPUs at one point; several posts noted the strategic implication for margins and API pricing rather than the unknown exact trick (@steph_palazzolo, @kimmonismus)A strong technical explainer traced NVIDIA programming’s evolution from Volta to Blackwell: from synchronous thread-centric CUDA to asynchronous dataflow across Tensor Cores, memory engines, barriers, TMA/TMEM, with detailed compute/bandwidth ratios for V100, A100, H100, B100 and examples from FlashAttention-3 and FlashMLA (@ZhihuFrontier)Agents, loops, evals, and memoryAI Engineer World Fair discourse strongly converged on “loops” / “loop engineering” as the new practical frame for agentic software: Andrew Ng described agentic coding, developer feedback, and external feedback loops as the operating model for AI-native product development (@AndrewYNg)The same theme appeared across conference chatter and tools: posts noted “loopcraft” in the keynote and heavy reuse of the term by OpenAI/Microsoft speakers and Peter Steinberger (@latentspacepod, @swyx)Agent evaluation infrastructure also advanced: LangChain integrated Harbor with Deep Agents, LangSmith Sandboxes, and Observability, positioning reproducible environment-based evals as becoming the standard for long-running/stateful agents (@LangChain, @hwchase17)Memory was another recurring topic: Harrison Chase and others highlighted wiki-style memory as one of the most promising agent memory patterns, with examples including DeepWiki, AutoWiki, LLM Wiki, and repeated emphasis that the hard part is not the storage backend but the condensation/retrieval process (@hwchase17, @BraceSproul)Models, benchmarks, and media releasesGoogle launched two media models: Nano Banana 2 Lite for images and Gemini Omni Flash for video generation/editing. Reported specs included
