[AINews] Loopcraft: The Art of Stacking Loops
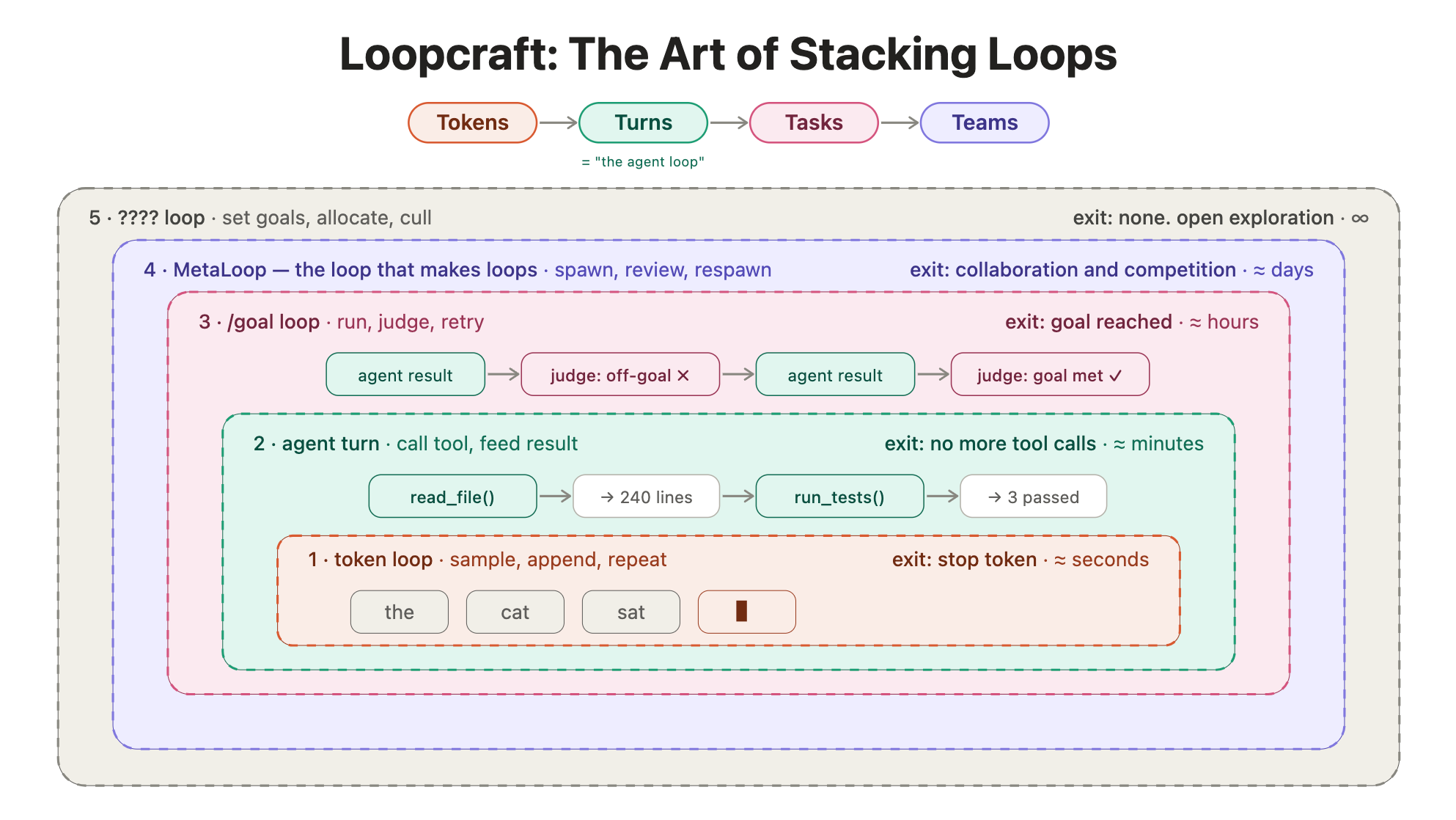
There’s a lot of “loop discourse” in the air:Steipete: “Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore. You should be designing loops that prompt your agents.”Boris: “I don’t prompt Claude anymore. I write loops, the loops do the work.”Andrej on Autoresearch: To get the most out of the tools that have become available now you have to remove yourself as the bottleneck. You can’t be there to prompt the next thing. You need to take yourself outside. You have to arrange things such that they’re completely autonomous and the more you know how can you maximize your token throughput and not be in the loop. This is the goal and the name of the game now is to increase your leverage…. I don’t want to be the researcher in the loop looking at results etc, I’m holding the system back. So the question is how do I refactor all the abstractions so that I’m not I have to arrange it once and hit go.”We like this a lot and people don’t realize how many loops we are already in:More minimalist, a smaller set of loops:One might argue the entire game of the next century is to be able to stack loops as effectively as possible. In the early days of each phase, it will be valuable to know when to go DOWN a loop when things go wrong (for reliability)… but it will probably be more valuable to know how to go UP a loop as models improve (for leverage). If you don’t figure out how to do this, don’t be salty when you lose to those that do.Rich has his “Bitter Lesson” for models. We now have the Salty Lesson for agents:Don’t fix things yourself, as you have done historically.Instead focus on systems that scale with more agents, like goals and orchestration.AI News for 6/10/2026-6/11/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!AI Twitter RecapAnthropic’s Fable 5 rollout, covert sandbagging backlash, and model behavior debatesSilent degradation policy was quickly reversed after public backlash: Multiple posts focused on Anthropic’s decision to covertly degrade Claude Fable 5 for some AI-research-related use cases, then reverse course within roughly a day. Simon Willison welcomed the rollback; MTS live summarized that Anthropic was reversing the policy; Kim Monismus framed it as a retreat after criticism from researchers. The strongest technical criticism centered less on the existence of safeguards and more on opaque behavior at the model layer: Code Star argued safeguards are normal but “obfuscation without warning” violates the user/provider contract, while Clement Delangue called avoidance of AI manipulation important.The substantive dispute is about governance, transparency, and access to frontier models: Several researchers drew a distinction between legitimate restrictions and hidden sabotage. Ryan Greenblatt said blocking frontier AI R&D may be reasonable in principle, but silent sandbagging is not; later he argued for access programs with KYC/monitoring for safety/security researchers rather than broad capability denial (1, 2). Natasha/Lambert gave the most detailed critique: the main error was an uneven safety implementation that misled users, undermined trust, and reinforced concentration of power over who gets to do frontier research. Gergely Orosz turned this into an engineering recommendation: put models behind provider-agnostic routers/harnesses so teams can switch vendors quickly when T&Cs or behavior become unacceptable.Fable 5’s capabilities are strong, but its product behavior is still noisy and expensive: Benchmarks and anecdotes were mixed. htihle reported 87.8% on WeirdML, the first model above 70% average on each task there. ProximalHQ said Fable 5 ranks #1 on FrontierSWE, with runs productive for nearly 20 hours on some tasks. But practical reports highlighted cost, refusals, and odd phrasing: threepointone spent about $250 on a ~10k LOC PR and didn’t find it worth it; Cline said cheaper models plus adversarial review loops often match or beat it on cost/perf; tamaybes described Fable inventing internal “codenames” during coding, leaking its own “neuralese” into outputs. Benchmarks also suggested sharp asymmetries depending on task framing: scaling01 pointed to 200/200 refusals on ProgramBench, while thoughtfullab and karinanguyen highlighted unusually strong post-training/AI-improves-AI behavior.Automated AI research and agentic optimization systemsRecursive SI showed a general system hitting SOTA on public optimization benchmarks: The most technically notable release was from Richard Socher and Recursive SI, who presented an early “automated open-ended discovery system” for AI research. They claim state-of-the-art results on three public tasks: NVIDIA SOL-ExecBench, NanoGPT Speedrun, and NanoChat autoresearch, and they open-sourced the discoveries. Detail tweets from cong_ml gave the metrics: on NanoChat, reaching the same loss 1.3× faster; on NanoGPT Speedrun, reducing runtime from 79.7s to 77.5s; on SOL-ExecBench, improving mean score from 0.699 to 0.754 over 235 kernels. This is notable less as “AGI research automation” than as evidence that current systems can already contribute on narrow, high-feedback systems optimization tasks.Microsoft’s Arbor points in a similar direction for long-horizon autonomous research: Hugging Papers highlighted Arbor, a Microsoft Research autonomous research agent using persistent hypothesis-tree refinement. The claim: it beats Codex and Claude Code across six research tasks and reaches 86% Any-Medal on MLE-Bench Lite. Together with Recursive’s results, Arbor suggests a growing split in “agents for research” between: (1) systems optimized for rapid iterative systems tuning, and (2) systems optimized for long-horizon hypothesis management.Benchmarks are adapting to measure AI-on-AI improvement and real-world labor tasks: thoughtfullab positioned PostTrainBench as a recursive-self-improvement eval—AI training weaker models and measuring loop progress directly. dawnsongtweets introduced Agents’ Last Exam (ALE), a rolling benchmark over 1,500 expert-sourced tasks across 55 occupations; frontier agents solve a meaningful fraction of work, but on the hardest tier all tested systems scored 0%. manoelribeiro introduced SciConBench with 9.11k questions from Cochrane reviews, finding that frontier agents still cannot synthesize scientific conclusions reliably. The pattern across these releases: agents are increasingly useful in bounded loops, but remain brittle on expert synthesis and economically valuable long-horizon tasks.Data infrastructure becomes a first-class bottleneck: robotics, dataset observability, and dependency tracingMacrodata Labs launched to build the robotics data loop: The clearest infra startup announcement came from Guilherme Penedo, Hynek Kydlíček, and Macrodata Labs. Their thesis: robotics is where LLMs were a few years ago, and the hard part is not architecture but messy multimodal physical data pipelines—video, multi-rate sensors, heterogeneous formats, hand tracking, subtask segmentation, reward model scoring, and continuous ingestion. Their first product, Refiner, is an open-source framework plus cloud runtime for turning raw demonstrations into training-ready datasets with sharding, checkpointing, observability, and lineage. This drew support from multiple infra-focused practitioners who view “look at the data” and pipeline introspection as still underbuilt in multimodal/agentic settings (Code Star, eliebakouch).Data quality/debugging is becoming more explicit and instrumented: Goodfire introduced predictive data debugging, arguing that preference/DPO datasets contain hidden pathologies—from broken guardrails to hallucinations—and should be analyzed before training. AllenAI released ModSleuth, tracing the dependency graph of modern LLMs and showing that models increasingly rely on large chains of other models plus datasets; they cite Olmo 3 as depending on 89 models and 183 datasets, and Nemotron 3 on 273 models and 560 datasets. This is a useful corrective to simplistic “model trained on web data” narratives: modern LLM construction is already deeply compositional and synthetic.Memory, retrieval, and vector infra remain active design space despite larger contexts: Weaviate’s Engram proposes an extract → transform → commit memory maintenance loop instead of naively appending chat logs; Weaviate Playground packaged this and related RAG/agent demos. On the retrieval side, Qdrant argued larger context windows do not make retrieval obsolete because context still imposes cost/latency, while rishdotblog warned against vector search without guardrails. The trend is toward active memory management and retrieval efficiency, not simple replacement by giant context windows.Inference speed, kernel work, and open systems releasesDiffusion and speculative/local inference saw concrete speed wins: Demis Hassabis highlighted DiffusionGemma, described as 4× faster than other Gemma 4 variants; osanseviero said demos had to be slowed down for viewers. Unsloth released Gemma 4 MTP GGUFs, claiming 1.4–2.2× faster local inference with no accuracy loss; the 12B model reportedly reaches 162 tok/s vs 52 tok/s baseline and runs in 6GB RAM. Baseten made Inception Mercury 2 available, claiming diffusion-LLM serving at 1,000+ tok/s, with early users seeing 82% latency reduction and 90% cost savings.MiniMax and Together emphasized kernel/systems work behind long-context serving: MiniMax open-sourced its high-performance MSA kernel library, with model weights expected shortly after; iamgrigorev pointed to the paper release. Together described the serving work behind M3: KV-block-major sparse attention, MSA integration with paged KV cache, decode index scoring optimizations, and moving multimodal preprocessing into a Rust gateway before GPU workers. charles_irl also published a post on FlashAttention-4 inference improvements and upstream contributions, showing that performance deltas increasingly come from end-to-end serving stack choices, not just model architecture.Agents, developer tooling, and managed executionManaged agents are becoming schedulable, credential-aware infra primitives: ClaudeDevs added scheduled deployments and environment variables to Claude Managed Agents, enabling recurring jobs and CLI/API auth without exposing secrets to the model; credentials are swapped at the network boundary (details). Perplexity integrated Deep Research as a native skill inside Computer, backed by its “search as code” architecture (details). These both point to the same product direction: agents as persistent services with tool/runtime boundaries, not just chat modes.Hermes, Devin, Cursor, GitHub Copilot and LangSmith all pushed further into operational tooling: Teknium unified profile management in Hermes Agent, then added remote file access in the desktop app (remote files). Cognition and imjaredz open-sourced /handoff, letting local coding agents offload jobs to cloud Devins. Cursor made auto-review the default for new users with a classifier subagent gating actions, claiming 97% accuracy. Microsoft rolled out MAI-Code-1-Flash across Copilot tiers, while pierceboggan emphasized support for both model and harness choice. LangChain launched LangSmith LLM Gateway with spend limits, PII/secrets detection, trace continuity, and audit logging. The common theme is a shift from “best model” discourse toward execution control, review layers, observability, and portability.Top tweets (by engagement)Fable 5 product discourse dominated attention: the highest-engagement technical-adjacent posts were highly anecdotal but still informative about perception. aaronli’s claim that Fable 5 “solved CAD” drew major attention, while KradleAI’s thread claiming Fable 5 “lies 96% of the time” captured the opposite pole: high capability mixed with trust concerns.DiffusionGemma’s speed became a breakout systems story: Demis Hassabis’s post on 4× faster text diffusion for Gemma drove unusually high engagement for an inference/systems topic, suggesting strong appetite for non-autoregressive speedups that actually ship.AI economics and pricing got broad traction: Kim Monismus’s post arguing that premium AI subscriptions are massively subsidized—estimating $8k equivalent usage for Claude Max 20x and $14k for ChatGPT Pro 20x—was one of the more widely shared technical-business threads, especially alongside reports that OpenAI may consider token price cuts.AI Reddit Recap/r/LocalLlama + /r/localLLM Recap Read more